Overview#
Usually we saw data systems provide extensibility by allowing user to define functions - UDF, in Nebula, we allow user to define custom column instead, there are some reasons:
- custom column is simpler - for reuse purpose, user define functions and use function in transformation, there are more places to handle this customized behavior. Custom column allows us to sumply focus on extra column computing.
- custom column is essential what user is looking for hence more straightforward. As mentioned above, most of time user defined function is for reuse purpose, however it is not a problem what Nebula tries to solve.
- Nebula core problem here is to allow user to define transformation through literal language -
javascript. - this aligns Nebula's another goal to enable user to run simple distributed machine learning algorithm, custom column will be
feature extractionin that use case.
Feature Support#
Support custom column as extensibility used by Nebula in two scenarios, they are:
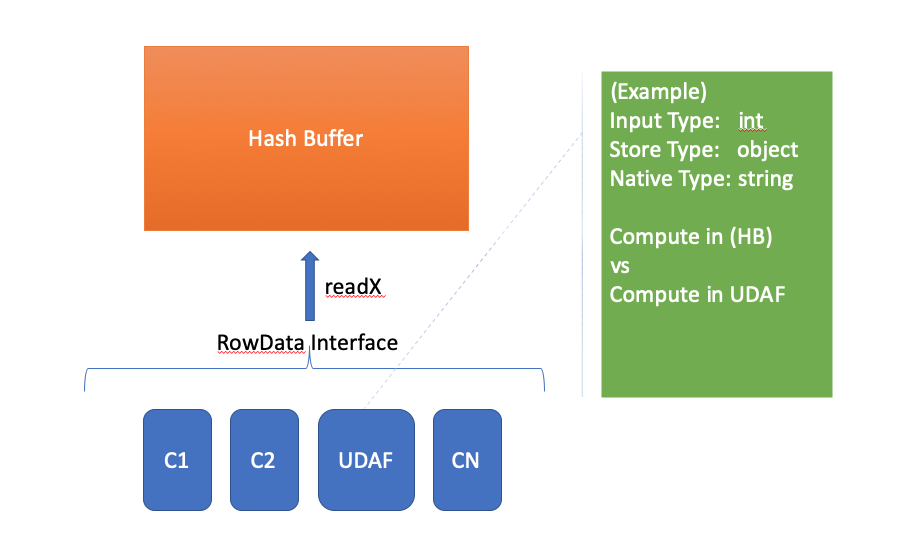
Runtime compute - user provide custom column in query, and we compute this custom column value for it. In this scenario, column definition is logical, column value is computed on the fly by observers, no persistent required here hence this custom column is not included in the table schema definition. for example:
``` // schema definition // table = ROW(a:int, b:long, c:string); // custom column definition const cc = () => nebula.column("a") * 2 + 3; nebula.register("cc", Types.INT, cc); // use the custom column in query table.select("cc");```Ingestion compute - user provides custom column hook in ingestion definition, it means original data source doesn't have the column, but we define it by lambda. This new computed column during ingestion time will be persisted hence included in table schema.
nebula.test: # max 10G RAM assigment max-mb: 10000 # max 10 days assignment max-hr: 240 schema: "ROW<id:int, price:double, price2:double>" columns: id: bloom_filter: true price2: expr: "[price] * 2"; time: type: static # get it from linux by "date +%s" value: 1565994194note that in this example,
[price]is just a convenient expression, in runtime, it will be converted to a real function satifying a javascript function definition asconst price2 = () => nebula.column("price") * 2
Internally, we're supporting ES2015 syntax standard javascript expression, this should give users flexible enough space to transform data to whatever they want.
More To Expect#
Nebula shall support custom aggregation column as well through javascript definition, however, it is a lot more work and we want to have a performant implementation of major aggregation functions, so this is not in the priority list for now.