We need extensible model to support adding any customized data structure for special data aggregation. It is challenge to make a decent design fitting into this requirements, let's take a look at what current system
- UDAF/UDF are modeled as generic expressions which represented by ValueEval or TypeValueEval in the runtime.
- ValueEval is extensible as long as it is visible, it has methods "eval" for value evaluation, "merge" for value merging, "stack" for value accumulation between different types.
- UDAF needs differentiate input type, runtime type and schema type so that it can finish aggregation life cycle.
- RowData interface is the generic interface used to exchange data between any compute layers.
- Expressions details are hidden by RowData interface which supports only readXXX methods for each individual supported types in our schema system.
- Sometimes it is not performant if we don't expose "input type" to compute layer when customized type is involved.
For example, if we're building a TDigest sketch for given expression typed in integer, assuming we have TDigestUDAF which defined types
- input type: INTEGER
- runtime type: TDigest Object modeled as "void*" or better std::shared_ptr<Serializable>
- schema type: VARCHAR
In computing time, when we iterate all rows, remember that the UDAF expression is hidden beind by a RowData interface which only allow a given column which contains the UDAF to expose one type, usually we expose runtime type, that means we only have RowData.readPointer(), the implication here is that we might end up with constructing/descruting huge number of TDigest objects, this doesn't sound correct and definitely not scalable for "customized" sketch.
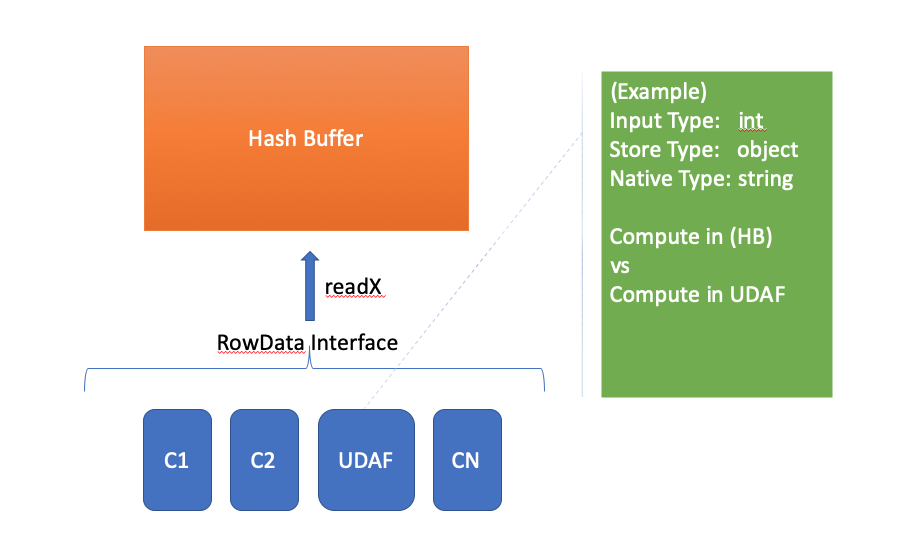
(External Compute: HB)
To overcome this hurdle, we have a few options to consider
- Expose UDAF as its inner expression, and leave its aggregation logic to external compute.
- e.g SUM(EXPR1) -> EXPR1 through RowData interface
- Sure, external compute will have enough metadata to understand how to invoke its logic for aggregation.
- Pros & Cons: very straightforward and leave data layer clean. The downside is the inconsistency in the schema, since most of the time, the UDAF result value type differs from its inner expression type.
- Expose different interface in RowData to allow external compute to fetch inner experssion value instead.
- This approach doesn't change its current runtime schema.
- Some kind of brokeness on RowData interface.
- Difficult to manage life cycle of the custom object since UDAF itself creates object internally and pass to external compute to manage.
None of above approaches is ideal and it is difficult to sort out an ideal approach for now. Here is what I propose to do to make this a bit cleaner hopefully:
- Mainly take approach 1 to keep UDAF interface clean and simple.
- Push complexity into HB by introducing aggregator object for each defined UDAF.
- The aggregator may or may not require extra object allocation, depends on if it needs assistant data structure.
- CreateObject
- Aggregate
- Serde
- We need to allow all UDAF to have different runtime schema but with final schema corrected in last stage.
Hopefully this change will help boost performance as well, for example AVG. Since this is going to be large refactoring, I will leave it to next diff and report back what the result looks like - the basic measure is ensure AVG UDAF is working well/better in the new design.
Update#
Through the whole Nebula code base, all the boundary is communicated through RowData and its cursor type RowCursor, it is extremely difficult to model a customized object (aggregator) on a plain storage wrapped by a RowData, and also to be very efficient to avoid object allocations across rows. I also looked at "struct" type, if we can reuse it to represent any customized sketch but attached with different functions, again it is good idea to keep RowData interface intact but facing two big challenges:
- construct sketch object on given memory chunk represented by the struct. (preventing object serde per row)
- avoid object creation for non-aggregated rows.
Given all the thoughts and exploration, I decided to make the change to RowData interface, adding a new interface to it to fetch aggregator object given column name/index. Client will get a valid aggregator object if
- the row represents an aggregated row
- the column is an aggregation column
otherwise it will return a nullptr.
Aggregation column type will be the same as its inner expression type, so that we know if a ROW can return normal value to be aggregated or it can return aggregator to aggregate other incoming values in block computing phase.
In merge phase - aggregator will aggregate other aggregators.
In final phase - an aggregator will provide finalize method to return its desired value.
In the new architecture, any sketch is attached and can be detached. As optimization, it may share memory as schema indicates which is controlled by column width. If the column is an aggregation field, it will produce alignment space for the column no matter it has null value or not.
When serialization, sketch will be serialized into data space, and deserialization will be restruct the sketch for each aggregation column.