Overview
Nebula is a block based data engine designed for optimizations on
- Extremely Fast Data Analytics.
- Tiered Data Storage.
- Secured Data Surface.
I would like to highlight a few top advantages that Nebula is presenting
- Hybrid columnar storage: depending on scenarios, Nebula dynamically switches between row-format and columar format data layout for speeding up computing or maximize throughput. For scenarios like data anonymization or data masking, Nebula may even choose pure columnar storage to minimize delta update to alter a specific column data.
- Comprehensive meta data system: meta data system is the brain of the whole system, query optimization, tiered data placement strategy and all other data synchronization are heavily depending on meta data system.
- Dynamic compression/encoding: to fit different access pattern, apply dynamic compression/encoding on different data for best compute efficiency and storage efficiency balance.
- Query interface and streaming interface: no matter it's analytics use case or data streaming use cases. The unified input as query interface, while unified output as streaming interface.
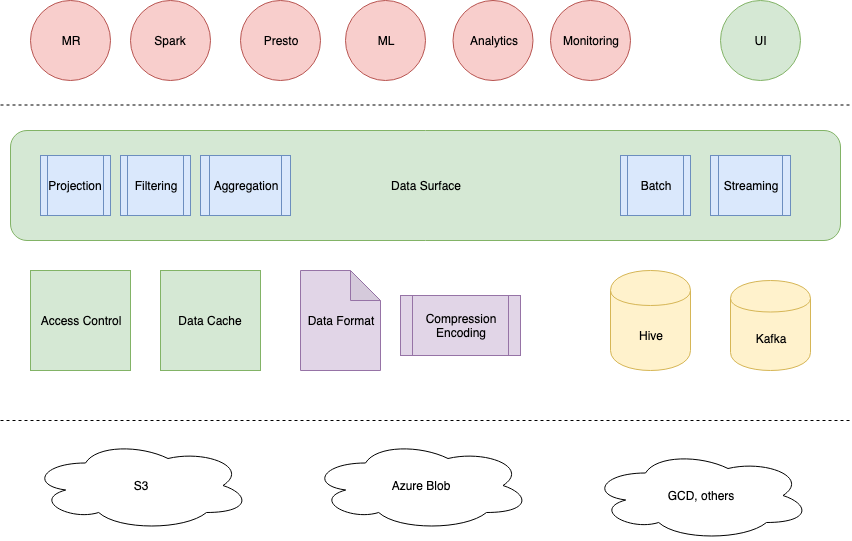
Architecture
To fit Nebula into the most common big data system, it could be partially illustrated as:
Security & Privacy#
For an organization, one of the most specific needs in big data system comparing to others is security and privacy requirements.
Connecting with the organization's authentication and authorization system is highly customized in Nebula. It operates as plugin model with a common interface.
Column Level Access Control#
Nebula data gateway requires user principal or access token to query Nebula service interface. The engine itself connects with customized authorization engine to retrieve access rules to decide reactions (pass, reject, masking, repalcement) on given actions (read/write on columns).
This provides a unified way to control data access in a fine-grained granularity.
Here is a detailed post explaining how access control works and how it looks, check it out... Nebula Access Control
Data Anonymization#
Reacting to retention policy of specific data, organizaitons which conduct online business are usually required to manage data properly so that they are following users' intention of how their data could be used. Anonymization is one approach to remove specific information but leaving statistical data for ML or analytics purpose.
Data Masking#
Lots of times, depending on access rules, not like anonymizaiton on data in storage itself, we want to replace hide or replace values of a specific column, we adopt masking techniques to fully or partially return data in acceptable format without change storage, some examples:
| Example Column | Return Values |
|---|---|
| xxx@gmail.com | |
| phone | 206-556-**** |
| password | NULL |
Data Encryption#
Data encryption is one option to allow people to access data with access key. This could be widely used by situations where rules engine is missing configured but allow anybody who has specific access token to access some columns.
Query System#
At the topmost layer, Nebula provide a SQL like DSL API for client to build up queries. A query can then be planned and sent to all nebula nodes to execute. It's easy to introduce SQL language as user interface to compile a text-based query into this API.
Query Planner will take this query object, compile it into an execution plan to execute. A code snippet showing how to build a query object.
const auto query = table(tbl, ms) .where(like(col("event"), "NN%")) .select( col("event"), col("flag"), max(col("id") * 2).as("max_id"), min(col("id") + 1).as("min_id"), count(1).as("count")) .groupby({ 1, 2 }) .sortby({ 5 }, SortType::DESC) .limit(10);Query Execution#
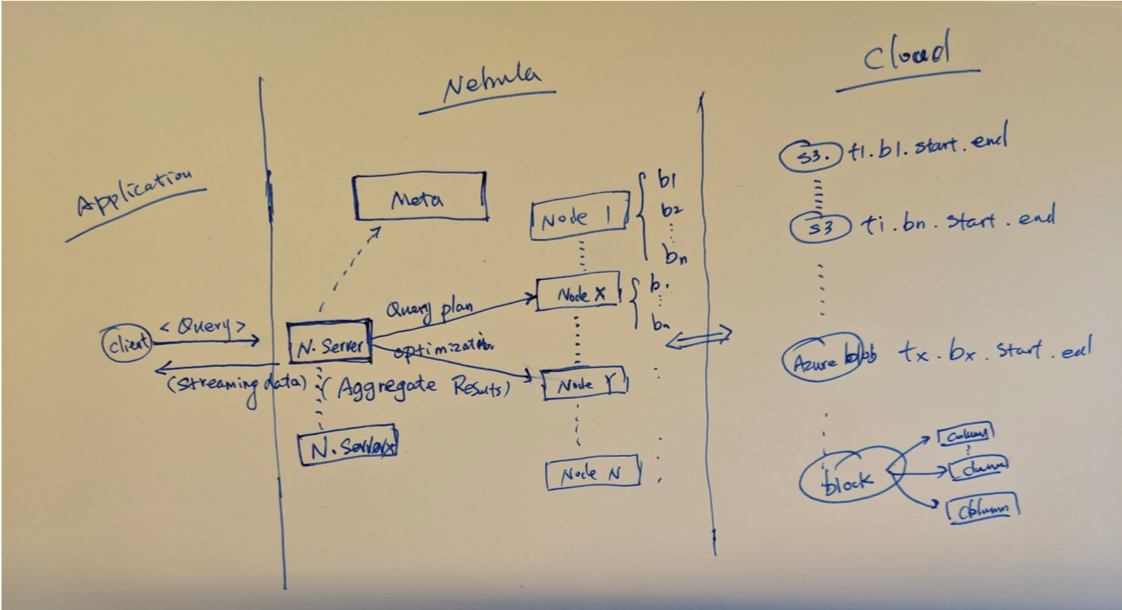
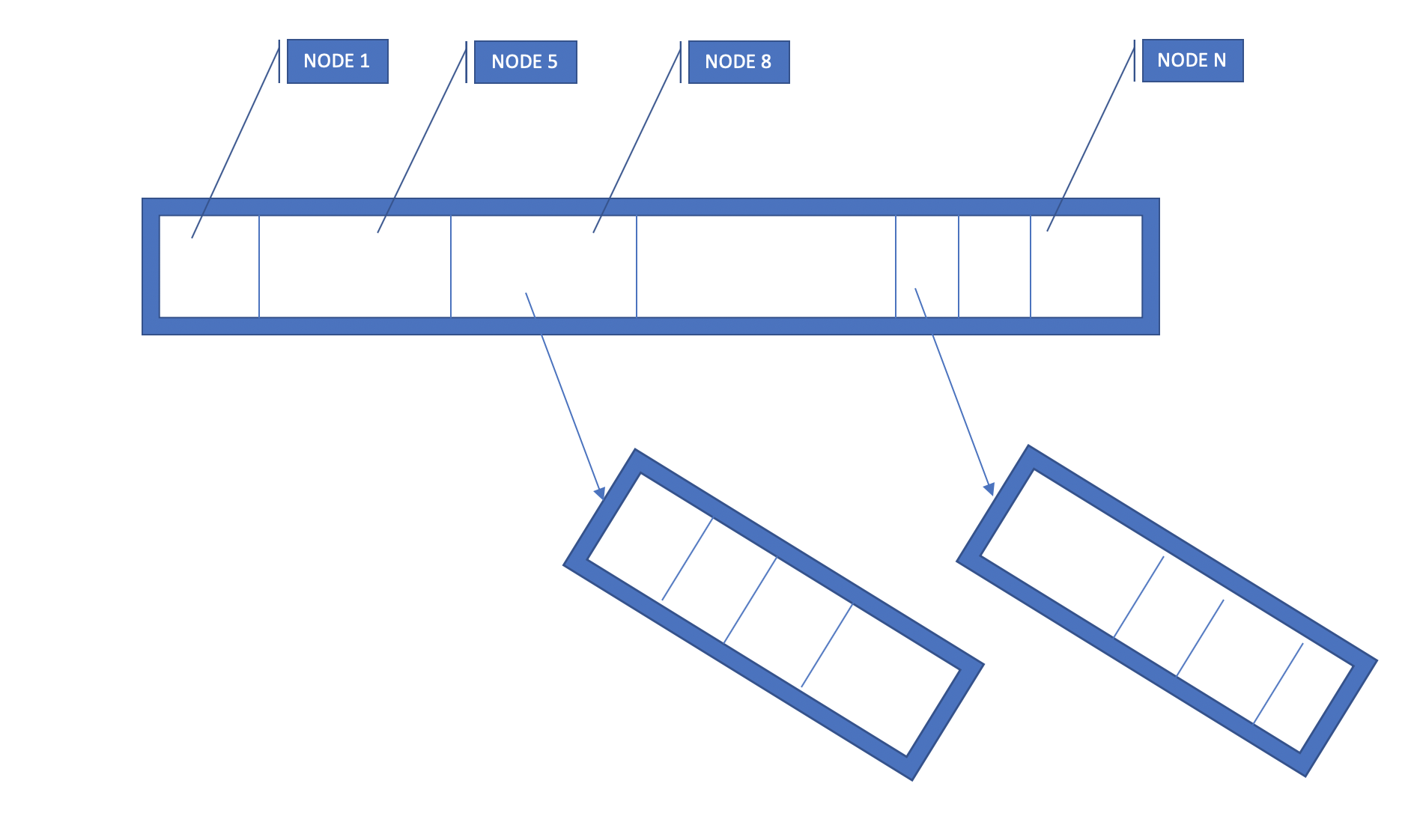
As we see how data is organized in nebula, we can quickly understand how query is executed, Nebula is a block-based data management system. Hence a block is not only the smallest chunk of data, it is also the smallest unit in compute parallism.
- Execution Model
- Fan-out execution to nodes according to planning on metadata.
- Partial aggregation at node level
- Global aggregation at query level
This raw draw shows the flow of query execution
- CPU cache friendly memory management
- Please refer related posts (future links) about the Nebula memory managment for its advantage on speed-up query.
- Vectorization and SIMD
- Nebula embraces fully vectorization computing and SIMD instructions.
- This is benefiting from its flexible memory format from ROW orientation to pure columnar orientation.
- Please refer related posts (future links) about the details of Nebula compute style for best speed.
UDF#
Nebula supports two types of UDFs.
- Built-in UDFs: universal common UDFs are supported natively, these includes but not limited to
- Basic Aggregations: COUNT, SUM, AVG
- Top: Min, Max
- Percentiles: Px (P25, P50, P90, P99, etc.)
- Cardinality: NDV (dictinct values),
- Others. (Please refer future Nebula Doc for details)
- User-provded Javascript Based UDF
- V8 engine integration.
- Generic row orientied interface to produce new columns.
- User can edit these type of UDF as part of thier interactive queries.
const my_udf = (row) => { // extract values let yValue = row.getString("column_y"); if(yValue == "abc"){ yValue = "NN"; }else if(yValue == "xyz"){ yValue = "NNNN"; }
// produce new columns return { "ncolumn_1": row.getInt("column_x") * 20, "ncolumn_2": yValue }; };
Visualization#
Nebula provides its own UI besides its API to provide tools for users to explore and visualize the data for meanings. In addition to the native visualizaiton methods such as
- Timeline
- Table
- Common charts like Bar, Pie, Line
Nebual also allows plugging different visualization engine to visualize query results, one outstanding example is Sanddance open sourced by Microsoft.
JOIN#
Nebula doesn't support common JOIN as it is designed as storage layer rather than a generic compute engine. However, some special super fast JOIN nebula considers to support in the future, such as Partitioned Hash Join. (We will update this section when related work is initialized.)
Streaming Interface#
Nebula supports streaming data over gRPC/HTTP2 stack of given query in below format
- Exchangable Data Format
- (NBlock) Nebula Block
- Arrow: high exchangable across multiple languages.
- JSON
- Optimization for light weight data to build UI
- Protobuf
- Optimization for application clients
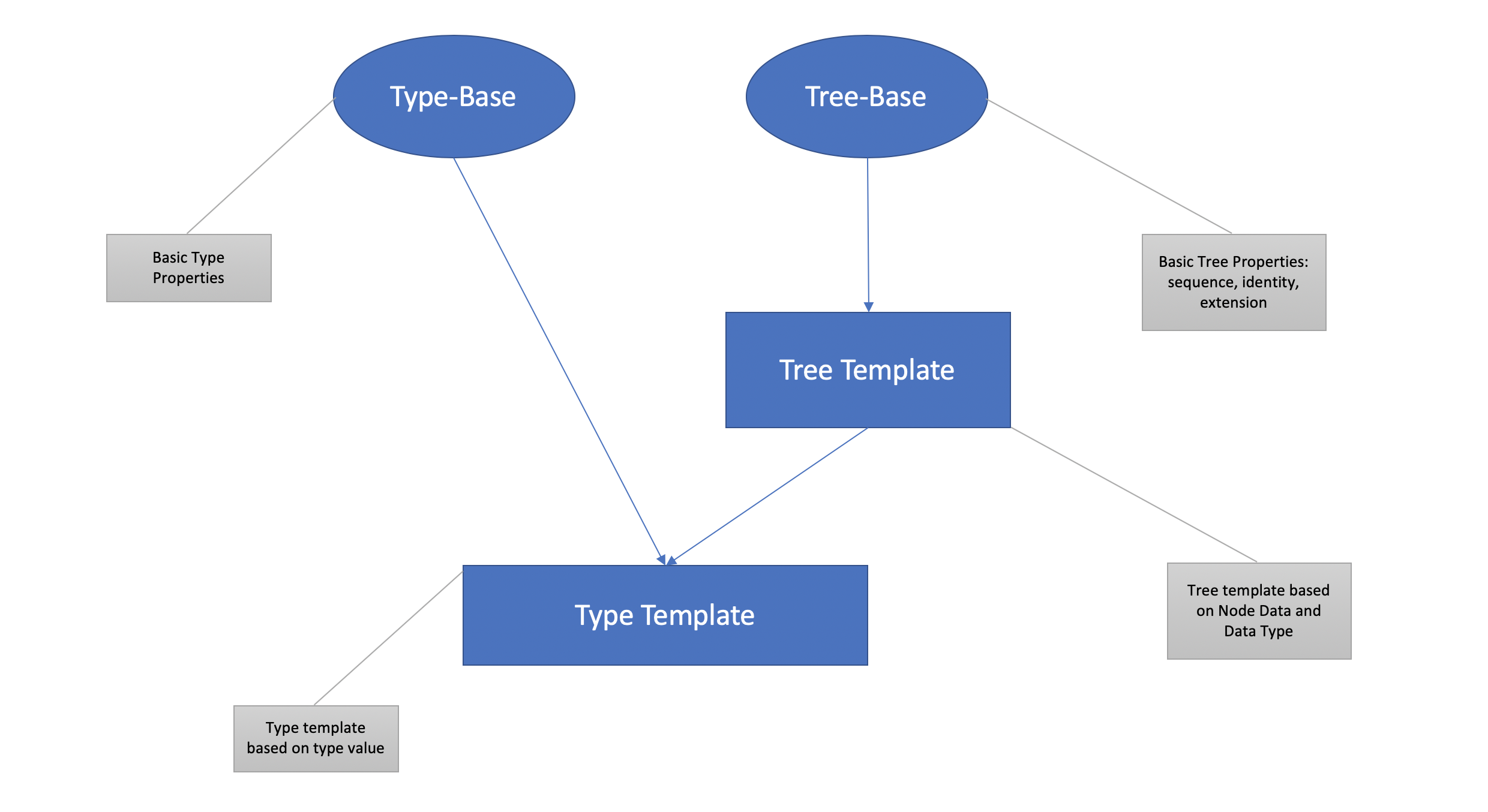
Type System#
Nebula treat schema as a type tree. Each leaf node is a primitive data node.
Non-leaf nodes represents compound types such as struct, list and map.
This type system is compatible with hadoop supported data schemas.
Schema Evolution & Backward Compability#
Nebula supports compatible schema evolution. This is achieved by two design options
- Every block has its own schema. When a block generated, it will produce a schema based on data and table schema definiton.
- Table schema evolution: a table schema can change time by time, however any changes/updates needs to backward compatible. These changes are legal
- Appending new columns
- Update columns with compatible types (e.g narrow numbers -> wide numbers, floats -> doubles)
- Query system will do best effort to match query schema with block schema, if no compatible data found, NULLs (or default values) will likely be replacement.
Metadata System#
(Placeholder)
Data Encoding Options#
Nebula applies different compression and encodings to different data to achieve least cost of memory consumption while achieve best compute efficiency.
Here is a list of encodings available for data.
| Type | Encodings | Metadata |
|---|---|---|
| bool | compressed bitmap | NULL-MAP |
| integers | RLE, delta | min/max/count/sum/HLL |
| string | dictionary, inverted index | index/histogram |
Ingestion
Theoridically, any readable data with schema defined can be ingested by Nebula. And it is Nebula's goal to cover as many type of data sources as possible to make itself as real data gateway.
However, Nebula curently focus on two different data sources
- Static Data (Hive Data)
- Realtime Data (Kafka Logs)
To illustrate how to configure new data source in Nebula, here are some examples:
# single data source swapable when udpates nebula.table1: max-mb: 40000 max-hr: 0 schema: "ROW<signature:string, user_id:long, comments:string, created_at:string>" data: s3 loader: Swap source: s3://<bucket>/nebula/comments/ backup: s3://nebula/n101/ format: csv | parquet columns: user_id: bloom_filter: true signature: bloom_filter: true time: type: column column: created_at pattern: "%Y-%m-%d %H:%M:%S"
# rolling data source day by day nebula.table2: max-mb: 200000 max-hr: 48 schema: "ROW<id:long, user_id:long, link_domain:string, title:string, details:string, signature:string>" data: s3 loader: Roll source: s3://<bucket>/nebula/messages/cd=%7Bdate%7D backup: s3://nebula/n103/ format: parquet columns: id: bloom_filter: true user_id: bloom_filter: true link_domain: dict: true time: type: macro pattern: date
# Kafka streams with maximum time to keep k.<topic>: max-mb: 200000 max-hr: 12 schema: "ROW<userId:long, type:short, statusCode:byte, objectCount:int>" data: kafka topic: <topic> loader: Streaming source: <brokers> backup: s3://nebula/n105/ format: thrift serde: retention: 90000 protocol: binary cmap: _time_: 1 userId: 3001 type: 3003 statusCode: 4002 objectCount: 4001 columns: userId: bloom_filter: true statusCode: default_value: 0 objectCount: default_value: 0 time: type: currentIn Nebula, Ingestion system can run in separate mode which is responsible to deliver data into backup space specified by each table. Nebula query system will sync data through metadata system.
Another mode supported by Nebula is mixed ingestion and query system in the same deployment. Howeer, in this case, ingestion tasks share the same compute resources with query system, hence they are in lower priority than query workload.
The latter option is usually used for small use cases who don't want multiple cluster setup. Ingestion system has its own challenges independently from query system. Please refer related posts (future links) to look deeper in this space.